
티스토리 뷰
[Kubernetes/k8s] Logging Architecture
KimDoubleB 2021. 8. 10. 19:13이 글은 쿠버네티스 공식문서의 '로깅 아키텍처'를 바탕으로 요약 및 생각정리를 한 글 입니다.
- 잘못된 부분이 있다면, 자유롭게 피드백 부탁드립니다 :)
- 더 자세한 내용이 보고 싶으시다면, 아래 공식문서를 참고해주세요.
로깅 아키텍처
애플리케이션 로그는 애플리케이션 내부에서 발생하는 상황을 이해하는 데 도움이 된다. 로그는 문제를 디버깅하고 클러스터 활동을 모니터링하는 데 특히 유용하다. 대부분의 최신 애플리케
kubernetes.io
컨테이너 엔진들도 로깅을 지원하도록 설계되었다 → 표준 출력, 표준 에러 스트림 작성
일반적으로 컨테이너 엔진이나 런타임에서 제공하는 기본 기능은 완전한 로깅 솔루션으로 충분하지 않다. 예를 들어, 컨테이너가 crash 되거나, Pod가 축출되거나, Node가 종료된 경우에도 애플리케이션의 로그에 접근하고 싶을 것이다.
그렇기에 클러스터에서 로그는 Node/Pod/Container 와는 독립적으로 별도의 Storage와 Life Cycle을 가져야 한다. 이 개념을 Cluster-level logging 이라고 한다.
Sample Pod
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args: [/bin/sh, -c,
'i=0; while true; do echo "$i: $(date)"; i=$((i+1)); sleep 1; done']1초에 한 번씩 표준출력
노드 레벨에서의 로깅

- 컨테이너화 된 애플리케이션의 stdout(표준출력), stderr(표준에러) 스트림에 의해 생성된 모든 출력을 컨테이너 엔진이 처리 및 리디렉션한다.
- 예를 들어, 도커 컨테이너 엔진이 이 두 스트림을 로깅 드라이버로 리디렉션한다. 이 드라이버는 쿠버네티스에서 JSON 형식의 파일에 작성하도록 구성된다.
- 기본적으로, 컨테이너가 다시 시작되면, kubelet은 종료된 컨테이너 하나를 로그와 함께 유지한다. 파드가 노드에서 축출되면, 해당하는 모든 컨테이너도 로그와 함께 축출된다.
- 노드-레벨 로깅에서 중요한 고려 사항은 로그 로테이션을 구현하여, 로그가 노드에서 사용 가능한 모든 스토리지를 사용하지 않도록 하는 것이다. 쿠버네티스는 로그 로테이션에 대한 의무는 없지만, 디플로이먼트 도구로 이를 해결하기 위한 솔루션을 설정해야 한다. (설정을 해줘야한다)
시스템 컴포넌트 로그
Kubernetes 자체 시스템 컴포넌트들의 로그는 '컨테이너에서 실행되는가'의 조건으로 2가지로 나눌 수 있다.
컨테이너에서 실행된다: kubernetes scheduler, kube-proxy
- 항상 /var/log 디렉터리에 기록
컨테이너에서 실행되지 않는다: kubelet , container runtime
- systemd를 사용하는 시스템이면 journald에 작성
- systemd를 사용하지 않는 시스템이면 /var/log 디렉터리의 .log 파일에 작성
시스템 컴포넌트는 klog 로깅 라이브러리를 사용한다.
kube-up.sh 스크립트로 구축한 쿠버네티스 클러스터에서 로그는 크기가 100MB를 초과하면 logrotate 도구에 의해 로테이트가 되도록 구성된다.
클러스터 레벨 로깅 아키텍처
노드 로깅 에이전트 사용
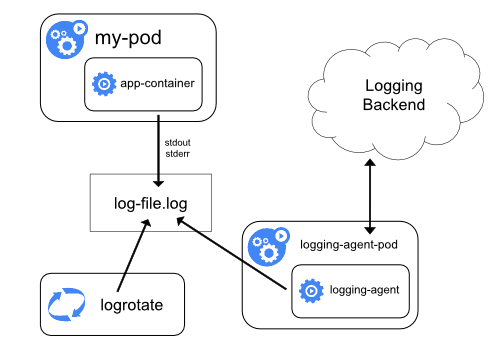
각 노드에 에이전트를 포함시켜 클러스터 레벨 로깅을 구현하는 방법
- 로깅 에이전트는 로그를 노출 및 백엔드로 푸시하는 도구
- 노드마다 존재해, 노드에 존재하는 모든 컨테이너의 로그파일에 접근할 수 있어야 한다.
에이전트는 노드별 하나씩 존재해야하므로, DaemonSet 으로 동작시키는 것이 추천된다.
노드 에이전트와 함께 사이드카 컨테이너 사용
사이드카 컨테이너를 이용한 2가지 방법
사이드카 컨테이너 스트리밍
- 사이드카 컨테이너가 애플리케이션 로그 자체를 원하는 형식으로 받아 stdout 으로 스트리밍 (로깅 에이전트 별도)
로깅 에이전트 사이드카 컨테이너
- 사이드카 컨테이너가 로깅 에이전트를 실행하며, 애플리케이션 컨테이너에서 로그를 가져오도록 구성
사이드카 컨테이너 스트리밍

사이드카 컨테이너가 자체 stdout, stderr 스트림을 사용
- 이러한 구조에서는 (이전 예제에서) 각 노드에서 이미 실행 중인 kubelet , 로깅 에이전트 를 사용할 수 있다.
이 방법을 사용하면 로직에 따라 여러 로그 스트림을 분리할 수 있고, stdout, stderr 가 kubelet 에서 처리되기 때문에 kubectl logs 같은 빌트인 도구를 활용할 수 있다.
해당 구조는 로그를 파일에 기록하고, 그것을 stdout 으로 스트리밍함으로 리소스 사용량이 증가할 수 있다. 고로, CPU 및 메모리 사용량이 낮다면, 다른 방법을 고려해보자.
예제로 2개의 사이드카 컨테이너를 가진 구조를 보자.
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-1
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/1.log']
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-log-2
image: busybox
args: [/bin/sh, -c, 'tail -n+1 -f /var/log/2.log']
volumeMounts:
- name: varlog
mountPath: /var/log
volumes:
- name: varlog
emptyDir: {}
로깅 에이전트 사이드카 컨테이너

- 노드 레벨의 로깅 에이전트를 사용하기에 충분히 유연하지 않은 경우, 애플리케이션 컨테이너와 함께 실행되도록 별도의 로깅 에이전트 사이드카 컨테이너를 활용할 수 있다.
- 사이드카 컨테이너에서 로깅 에이전트를 사용하는 것인데, 이 방식도 상당한 리소스 소비로 이어질 수 있다. 또한, kubelet 에 의해 제어되지 않기 때문에 kubectl logs 같은 로그 빌트인 도구를 사용하지 못한다.
- fluentd 를 사용한 예제
apiVersion: v1
kind: ConfigMap
metadata:
name: fluentd-config
data:
fluentd.conf: |
<source>
type tail
format none
path /var/log/1.log
pos_file /var/log/1.log.pos
tag count.format1
</source>
<source>
type tail
format none
path /var/log/2.log
pos_file /var/log/2.log.pos
tag count.format2
</source>
<match **>
type google_cloud
</match>apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i: $(date)" >> /var/log/1.log;
echo "$(date) INFO $i" >> /var/log/2.log;
i=$((i+1));
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
volumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
애플리케이션에서 직접 로그 노출

- 이 방식은 쿠버네티스의 관리 범위를 벗어난다. 어플리케이션에서 구축하는 것.
결론
뭐가 제일 좋을까에는 답이 없다고 생각한다.
방법마다 장단점이 나뉘고, 현재 쿠버네티스/서버 구성 상황에 따라 달라질 것 같다.
Logging agent를 새로운 Pod으로 구성하는 법 (DaemonSet 이용)
- 구성에서 깔끔하다. 모든 Pod 에서 중복되지 않고, 노드 당 하나를 만족시켜 리소스를 많이 소비하지 않을 수 있다.
- 하지만 Logging agent가 log를 인식해 가져갈 수 있도록, 모든 어플리케이션들이 특정한 위치에 log file을 생성해야 함. default가 /var/log 로 설정했다면, 특정 어플리케이션이 로그 위치를 수정하지 않도록 해야함.
Logging sidecar pattern (하나의 Pod에 logging container 존재)
- Application에서 Logging을 생각하지 않아도 됨. 개발에만 집중할 수 있음. Logging에 대한 역할과 책임을 아예 delegate 가능. Sidecar 형태로 자동주입된다면 kubernetes 구성하는데도 매우 편하게 구성 가능.
- Logging container를 어떻게 설치할 것인가가 중요하다고 생각. Sidecar pattern으로 구성하려면 istio 에서 envoy 를 sidecar pattern으로 자동으로 넣어주듯이 비슷하게 자동으로 넣어주는 식으로 구성하지 않는다면... 수동으로 위처럼 작성해줘야 하는 문제가 발생할 수 있을 것 같음?
- 모든 Pod마다 생성되서 리소스 부하가 커질 수 있음. 여기서도 istio, envoy 를 예로 들자면, Sidecar pattern에선 pod 별로 다 설치가 되어 큰 프로젝트일수록 부하 문제를 생각해야 함. 그래서 Service mesh에서 가장 자료가 많은 istio 지만 도입하려면 성능 문제를 먼저 생각해야 할 정도. 하지만 istio - envoy 는 이러한 문제를 해결하고자 엄청 가볍고, 빠르게 동작할 수 있도록 구현되었음. 즉, 이러한 logging sidecar 패턴을 구성한다면 마찬가지로 성능, 부하 관련해서 고려해야한다고 생각.
'Development > Docker & Kubernetes (K8s)' 카테고리의 다른 글
| [Kubernetes/k8s] kubernetes logs 데이터는 어디에 저장될까 ? (2) | 2021.09.03 |
|---|---|
| [Docker] docker logs 데이터는 어디에 저장될까 ? (MacOS) (1) | 2021.09.03 |
| Docker & Kubernetes - bash로 접속하기 (0) | 2021.08.09 |
| [Istio] Istio DestinationRule 리소스 제공 옵션(Spec) 설명 (0) | 2021.07.06 |
| [Kubernetes/k8s] api group 이란? (0) | 2021.07.01 |
- Total
- Today
- Yesterday
- Spring
- Intellij
- 하루
- Kubernetes
- 로그
- HTTP
- 일상
- Clean Architecture
- c++
- tag
- gradle
- MySQL
- Spring boot
- 쿠버네티스
- Istio
- OpenTelemetry
- 알고리즘
- container
- boj
- docker
- k8s
- Log
- 백준
- java
- jasync
- 비동기
- 클린 아키텍처
- Algorithm
- python
- WebFlux
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 | 31 |